- ModuleAutonomous Robotics Systems
- Date09/2021-12/2021
- CategoryMachine Learning
- MarksFirst-class
Read my report on the project
Cartpole Animation
Reflections
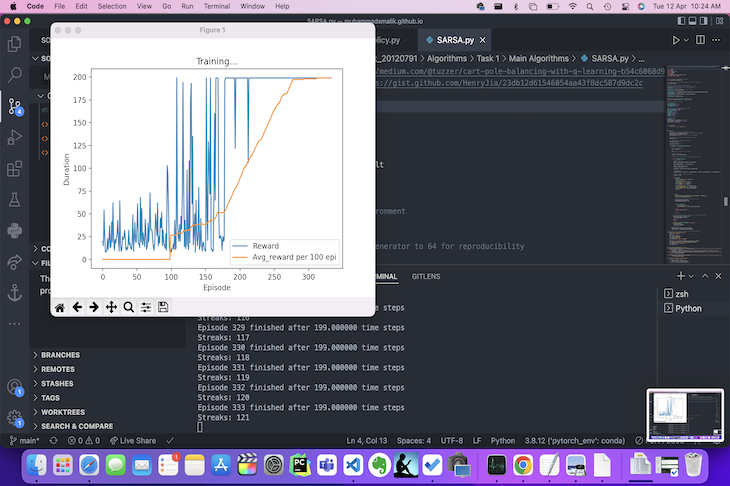
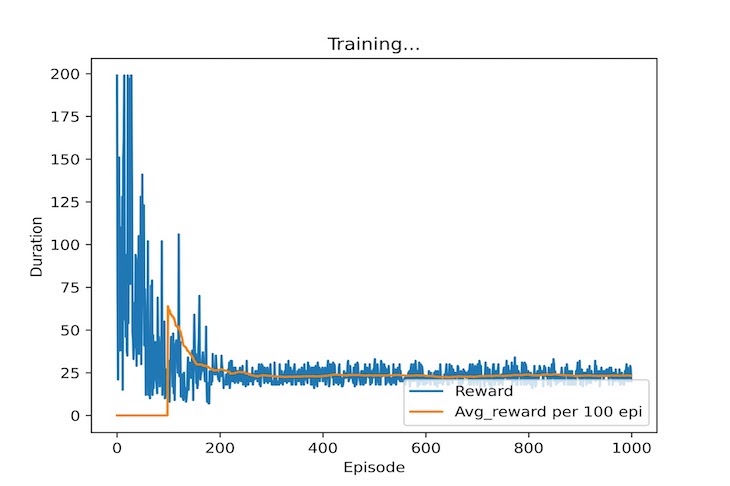
In my previous semester, I took a masters-level course on Autonomous Robotics Systems, the course was initially meant to have us work with physical robots and implement reinforcement learning algorithms to them, but unfortunately due to the pandemic and lack of in-person teaching, my lecturer came up with the creative idea of having us use a virtual playground for AI known as OpenAIGym. This playground allowed me to implement and experiment with a range of different Reinforcement learning algorithms from a Q-Learning algorithm all the way up to a Deep-Q learning algorithm which implements a neural network in place of the Q-Table used in Q-Learning, while also taking a shot at creating a good heuristic (Hard-coded) implementation that could possibly solve the CartPole problem even faster than the reinforcement learning algorithms!
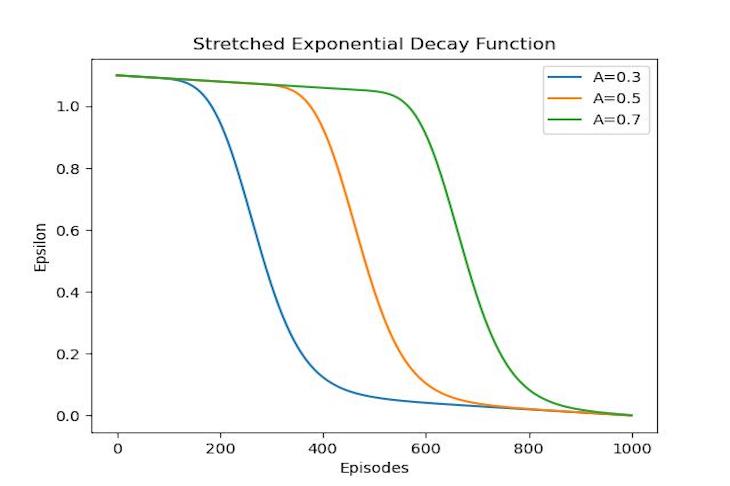
The most interesting part of playing around with these learning agents was watching how they adapted from their failures, as reinforcement learning algorithms each have their own reward/punishment structure which can be modified to affect how the agent learns from its environment. The more the agent fails, the more it knows to try different options in an attempt to get a better reward while also inadvertently gaining more knowledge which it can exploit towards the same goal. Even though learning is important though (I mean it's literally in the name) it can be equally as important that the agent also tries to explore and try options that might be less favourable than others, as it allows the agent to possibly find more efficient paths to success which it wouldn't have found otherwise if it only followed what it thought was the best possible path.
It's a weird conundrum learning about and working with Reinforcement learning agents, as you're not only trying to decipher the code and theory that goes into the making of an agent but also, trying to understand how the structure of a machines thought process for solving problems dynamically can be so similar and yet so different from our own.